TF-IDF (Term Frequency-Inverse Document Frequency) (টিএফ-আইডিএফ)
TF-IDF (Term Frequency-Inverse Document Frequency) (টিএফ-আইডিএফ)

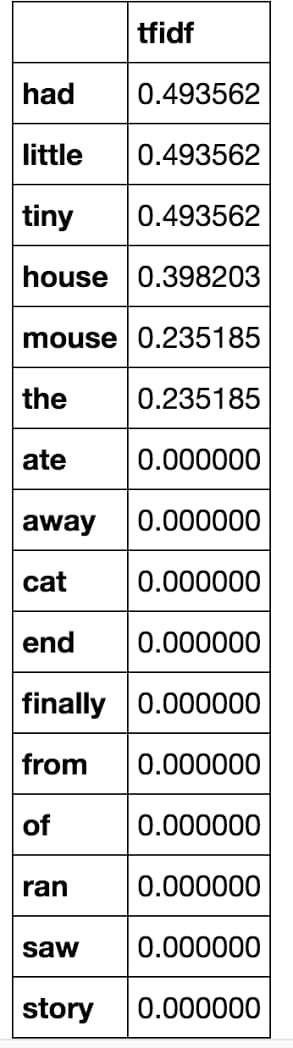
==============================
আমি তোমাকে এক গল্পের মাধ্যমে TF-IDF (Term Frequency-Inverse Document Frequency) কনসেপ্টটা ব্যাখ্যা করতে চেস্টা করব।
গল্পের শুরু:
ধরো, তুমি এবং তোমার কয়েকজন বন্ধু একসাথে স্কুলের একটি বইয়ের ক্লাব চালাও। এই ক্লাবের নাম “বইয়ের জগৎ”। তোমাদের লাইব্রেরিতে অনেক বই আছে, তবে সমস্যা হচ্ছে—সবাই সব বই পড়তে পারে না। তোমরা চাও, প্রত্যেককে এমন কিছু বই সাজেস্ট করা হোক, যেগুলো তাদের পছন্দের বিষয়ে বেশি তথ্য দেয়।
তোমাদের ক্লাবের দুই গুরুত্বপূর্ণ সদস্য হলো টনি আর সারা। টনি এবং সারা দুজনই বই সাজেস্ট করার দায়িত্ব পেয়েছে। কিন্তু সমস্যাটা হলো, বইগুলোতে অনেক শব্দ এমন আছে যা মোটামুটি সব বইতেই থাকে—যেমন, “the”, “is”, “of”, “in”, ইত্যাদি। আবার কিছু শব্দ আছে যা নির্দিষ্ট বইয়ের জন্য খুবই গুরুত্বপূর্ণ, যেমন ‘রোবটিক্স’, ‘প্ল্যানেট’, ‘কোয়ান্টাম’, ইত্যাদি।
এখন টনি এবং সারা মিলে একটা সিস্টেম তৈরি করল, যাতে তারা সহজেই নির্ধারণ করতে পারবে কোন বইয়ে কোন শব্দ বেশি গুরুত্বপূর্ণ, এবং কোন শব্দ সবার কাছে অপ্রয়োজনীয়।
গল্পের মধ্যকার TF-IDF:
১. Term Frequency (TF):
টনি বলে, “প্রথমে আমরা দেখতে পারি, বইয়ের ভিতরে কোনো নির্দিষ্ট শব্দ কতবার এসেছে।”
ধরো, টনি দেখতে পেল, যে এক বইয়ে ‘রোবটিক্স’ শব্দটি ১৫ বার এসেছে। আরেক বইয়ে ‘রোবটিক্স’ শব্দটি ৫ বার এসেছে। এটি হলো সেই বইগুলোর ভিতরে ‘রোবটিক্স’ শব্দের Term Frequency (TF)।
২. Inverse Document Frequency (IDF):
এবার সারা বলে, “আমরা তো শুধু বইয়ের ভেতরের শব্দ সংখ্যা গুণে দেখতে পারি না। পুরো লাইব্রেরির সব বইতে যদি ‘রোবটিক্স’ শব্দটা থাকে, তবে এই শব্দটা তেমন গুরুত্বপূর্ণ হবে না। কিন্তু যদি ‘রোবটিক্স’ কিছু নির্দিষ্ট বইতেই থাকে, তবে এই শব্দটা সেই বইয়ের জন্য খুব গুরুত্বপূর্ণ হবে।”
এভাবে সারা বুঝিয়ে দিলো Inverse Document Frequency (IDF) কনসেপ্টটা। যদি কোনো শব্দ অনেকগুলো বইতে থাকে, তাহলে তার গুরুত্ব কমে যাবে। আর যদি শব্দটি কম সংখ্যক বইতে থাকে, তাহলে সেটি সেই বইয়ের জন্য অনেক গুরুত্বপূর্ণ হয়ে যাবে।
৩. TF-IDF মডেল:
এবার টনি ও সারা দুইটা জিনিস মিলে (TF এবং IDF) একটা স্কোর বানালো। এই স্কোর হলো TF-IDF। তারা ঠিক করলো, যেই শব্দের TF-IDF স্কোর বেশি হবে, সেই শব্দটা সেই বইয়ের জন্য গুরুত্বপূর্ণ হবে।
উদাহরণ:
ধরো, তোমাদের লাইব্রেরিতে তিনটা বই আছে:
1. প্রথম বই: “রোবটিক্সের পরিচিতি”।
2. দ্বিতীয় বই: “মহাবিশ্বের রহস্য”।
3. তৃতীয় বই: “রোবটিক্স এবং মহাকাশ গবেষণা”।
এখন, টনি দেখলো যে ‘রোবটিক্স’ শব্দটি প্রথম বইয়ে ১৫ বার, দ্বিতীয় বইয়ে ১ বার, এবং তৃতীয় বইয়ে ২০ বার এসেছে। এই শব্দের Term Frequency (TF) খুবই বেশি।
কিন্তু সারা খেয়াল করলো, ‘রোবটিক্স’ শব্দটি দুইটা বইয়ে বেশি পরিমাণে থাকলেও, দ্বিতীয় বইয়ে খুব কম আছে। সুতরাং এই শব্দটা পুরো লাইব্রেরির জন্য অতটা গুরুত্বপূর্ণ নয়। তাহলে, ‘রোবটিক্স’ এর IDF স্কোর কম হবে, কারণ এটি অনেক বইয়ে পাওয়া যায়। কিন্তু ‘মহাবিশ্ব’ বা ‘গবেষণা’ শব্দগুলো কম বইতে পাওয়া যায়, তাই তাদের IDF স্কোর বেশি হবে।
কেন এটা দরকার?
এখন, যদি তোমার একজন বন্ধু ‘রোবটিক্স’ নিয়ে কোনো বই পড়তে চায়, তাহলে টনি এবং সারা মিলে তাকে এমন একটি বই সাজেস্ট করবে, যেখানে ‘রোবটিক্স’ শব্দটির TF-IDF স্কোর সবচেয়ে বেশি, যেমন “রোবটিক্স এবং মহাকাশ গবেষণা”। কারণ এই বইতে ‘রোবটিক্স’ শব্দটি শুধু বেশিবার এসেছে তাই নয়, এটি বইটির জন্য সবচেয়ে গুরুত্বপূর্ণও।
সারমর্ম:
TF-IDF হলো এমন একটি মডেল, যা কোনো বই বা ডকুমেন্টে কোন শব্দ কতবার এসেছে (TF) এবং সেটি কতগুলো ডকুমেন্টে পাওয়া যায় (IDF) দেখে ঠিক করে, কোন শব্দটা গুরুত্বপূর্ণ।
গল্পের মাধ্যমে তোমরা বুঝতেই পারলে, কীভাবে টনি এবং সারা এই মডেল ব্যবহার করে লাইব্রেরির সবচেয়ে গুরুত্বপূর্ণ বই বের করতে পারে, এবং তোমাদের ক্লাবের সদস্যদের সহজে সাজেস্ট করতে পারে।
কীভাবে গাণিতিক বা পরিসংখ্যানিকভাবে কাজ করে:
===========================
এবার আমরা একটু গভীরে ঢুকে দেখবো যে TF-IDF (Term Frequency-Inverse Document Frequency) কীভাবে গাণিতিক বা পরিসংখ্যানিকভাবে কাজ করে। আমি একটি গল্পের মাধ্যমেই এই কনসেপ্টটি ব্যাখ্যা করবো।
গল্পের শুরু:
ধরো, তুমি একজন মাষ্টারশেফ এবং তোমার একটি রেস্তোরাঁ আছে। প্রতিদিন অনেক গ্রাহক আসে এবং বিভিন্ন রেসিপির প্রশংসা করে। কিন্তু তোমার চ্যালেঞ্জ হলো, এই প্রশংসাগুলোর মধ্যে কোনটি আসলে সত্যিই গুরুত্বপূর্ণ, সেটি বের করা।
তুমি কী করবে? তুমি খুঁজে বের করতে চাও, কোন গ্রাহকের মন্তব্যগুলো সত্যিই গুরুত্বপূর্ণ, এবং কোনগুলো শুধুই সাধারণ শব্দভাণ্ডার।
এখন, TF-IDF ঠিক এই কাজটাই করে। এটা খুঁজে বের করে, কোন শব্দগুলো বিশেষ গুরুত্বপূর্ণ এবং কোনগুলো সব জায়গাতেই থাকছে।
১ম ধাপ: Term Frequency (TF)
একদিন, তুমি এবং তোমার সহকারী প্রতিটি গ্রাহকের মন্তব্য বিশ্লেষণ করতে বসলে। প্রথমে তোমরা লক্ষ্য করলে, কতবার প্রতিটি শব্দ মন্তব্যের মধ্যে এসেছে।
ধরো, তোমার রেস্তোরাঁ সম্পর্কে এক গ্রাহকের মন্তব্য হলো:
“The pasta was delicious and the sauce was amazing!”
এখন, “pasta” শব্দটি এখানে একটি বিশেষ শব্দ। কিন্তু কতবার এটি এসেছে? এখানে এটি একবারই এসেছে। এটিকে আমরা বলবো Term Frequency (TF)।
TF-এর জন্য ফর্মুলা হলো:
\text{TF(word)} = \frac{\text{Number of times the word appears in the document}}{\text{Total number of words in the document}}
এই ফর্মুলা অনুযায়ী, “pasta” এর জন্য TF হবে:
\text{TF(pasta)} = \frac{1}{8} = 0.125
২য় ধাপ: Inverse Document Frequency (IDF)
এখন তুমি দেখলে, কিছু শব্দ যেমন “the”, “was”, “and” প্রায় প্রতিটি মন্তব্যেই থাকে। এগুলো সাধারণ শব্দ, তাই এগুলো এতটা গুরুত্বপূর্ণ নয়। আমরা এগুলোর গুরুত্ব কমিয়ে দেবো।
এই কাজটি করে Inverse Document Frequency (IDF)। এটি বলে দেয়, কোনো শব্দ যদি কম সংখ্যক মন্তব্যে থাকে, তবে সেটি অনেক বেশি গুরুত্বপূর্ণ। আর যদি শব্দটি বেশিরভাগ মন্তব্যেই থাকে, তবে তার গুরুত্ব কমে যাবে।
IDF-এর ফর্মুলা হলো:
\text{IDF(word)} = \log \left( \frac{\text{Total number of documents}}{\text{Number of documents containing the word}} \right)
ধরো, তোমার মোট ১০০টি মন্তব্য রয়েছে, এবং এর মধ্যে “pasta” এসেছে মাত্র ১০টি মন্তব্যে। তাহলে, “pasta” এর জন্য IDF হবে:
\text{IDF(pasta)} = \log \left( \frac{100}{10} \right) = \log(10) = 1
৩য় ধাপ: TF-IDF হিসাব
এবার, TF এবং IDF কে একত্রিত করে আমরা একটি TF-IDF স্কোর পাবো। এটি বলবে, কোন শব্দটি পুরো মন্তব্যের মধ্যে কতটা গুরুত্বপূর্ণ।
TF-IDF এর জন্য ফর্মুলা হলো:
\text{TF-IDF(word)} = \text{TF(word)} \times \text{IDF(word)}
আমাদের উদাহরণে “pasta” এর জন্য TF-IDF হবে:
\text{TF-IDF(pasta)} = 0.125 \times 1 = 0.125
এভাবে, যদি আমরা “the” বা “was” এর মতো সাধারণ শব্দের জন্য TF-IDF স্কোর বের করি, তবে তাদের IDF স্কোর খুব কম হবে, কারণ এই শব্দগুলো অনেক মন্তব্যে থাকে। তাই তাদের TF-IDF স্কোরও কমে যাবে।
সংক্ষেপে:
TF-IDF একটি মডেল যা নির্ধারণ করে, কোন শব্দ একটি নির্দিষ্ট ডকুমেন্ট বা মন্তব্যের জন্য কতটা গুরুত্বপূর্ণ। TF বলে দেয় কতবার কোনো শব্দ এসেছে, আর IDF বলে দেয় কত কম মন্তব্যে সেই শব্দটি পাওয়া যায়। যখন এই দুটি একসাথে হয়, তখন আমরা পেয়ে যাই একটি নির্দিষ্ট মন্তব্যে বা ডকুমেন্টে কোন শব্দটি সবচেয়ে গুরুত্বপূর্ণ, সেটি।
গল্পের শেষ:
তুমি এবং তোমার সহকারী এবার প্রতিটি গ্রাহকের মন্তব্য বিশ্লেষণ করে দেখলে, কোন শব্দগুলো তোমার রেস্তোরাঁর খাবার সম্পর্কে বিশেষ উল্লেখযোগ্য, আর কোনগুলো কেবল সাধারণ কথাবার্তা। এই বিশ্লেষণ তোমাকে সাহায্য করবে গ্রাহকদের আসল চাহিদা এবং প্রশংসা বুঝতে, যাতে তুমি তোমার রেস্তোরাঁকে আরও উন্নত করতে পারো।
এভাবেই, TF-IDF মডেলটি ম্যাথমেটিক্যালি এবং স্ট্যাটিস্টিকালি কাজ করে!
***কমেন্ট next

