সেমান্টিক ইনডেক্স বা ভেক্টর স্টোরেজ:
সেমান্টিক ইনডেক্স বা ভেক্টর স্টোরেজ:
**********************************
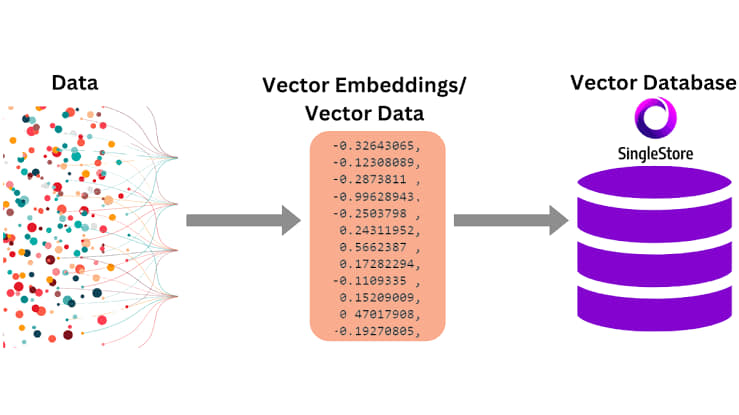
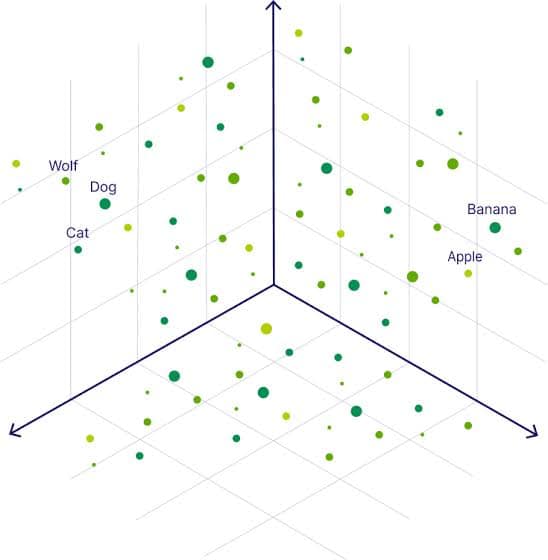
.
কল্পনা করুন, আপনি একটি বিশাল লাইব্রেরিতে প্রবেশ করেছেন। এই লাইব্রেরি শুধুমাত্র বইয়ের শিরোনাম বা লেখকের নাম দিয়ে সাজানো হয়নি, বরং প্রতিটি বইয়ের ভেতরের ভাবনা, অনুভূতি এবং তথ্যও এখানে সঞ্চয় করা হয়েছে। এটি একটি অদ্ভুত লাইব্রেরি, যেখানে বইগুলো তাদের বিষয়বস্তু অনুযায়ী সাজানো হয়েছে, যাতে আপনি সহজেই আপনার অনুসন্ধান করতে পারেন।
ভেক্টর স্টোরেজের মূল উপাদান
১. এম্বেডিং: তথ্যকে ভেক্টরে রূপান্তর করা
ধরুন, লাইব্রেরির একজন গ্রন্থকর্মী আছে, যার নাম অ্যালেক্স। অ্যালেক্স জানে যে, বিভিন্ন বইয়ের বিভিন্ন বিষয় আছে, কিন্তু সেগুলো একে অপরের সাথে কিভাবে সম্পর্কিত, সেটি বুঝতে হবে। তাই, অ্যালেক্স প্রতিটি বইয়ের মূল ভাবনা, কাহিনী এবং বিষয়বস্তু নিয়ে একটি সংখ্যা তৈরি করে। এই সংখ্যাগুলোকে ভেক্টর বলা হয়। যেমন, “সঙ্গীত” ও “গান লেখা” বিষয়ক বইগুলো একই ধরনের সংখ্যা পায়, কারণ তাদের মধ্যে সম্পর্ক আছে।
২. ভেক্টর স্পেস:
অ্যালেক্স এরপর এই ভেক্টরগুলোকে একসাথে একটি বিশেষ জায়গায় সঞ্চয় করে, যা একটি 3D এর মত যেখানে দৈর্ঘ্য প্রস্থ এবং উচ্চতা আছে। ফিজিক্সে যেটাকে এক্স ওয়াই অথবা জেড অক্ষ হিসেবে চিন্তা করা হয় তেমন যাকে ভেক্টর স্পেস বলে ভাবা যায়। এখানে প্রতিটি ভেক্টর একটি নির্দিষ্ট স্থান দখল করে, এবং তাদের মধ্যে সংযোগ রয়েছে। আপনি যদি ভাবেন, একটি 3D স্পেসের মধ্যে বইগুলো কিভাবে স্থান পায়, তাহলে দেখতে পাবেন যে, সঙ্গীত ও গান লেখা বইগুলো একে অপরের কাছে থাকে।
৩. সাদৃশ্য মাপা: অর্থের (meaning)সম্পর্ক বোঝা
যখন কেউ একটি বই খোঁজার জন্য লাইব্রেরিতে আসে, অ্যালেক্স দূরত্ব মাপার একটি পদ্ধতি ব্যবহার করে। সে ভেক্টরগুলোর মধ্যে দূরত্ব পরিমাপ করে (যেমন কসাইন সিমিলারিটি) এবং দেখতে পারে কোন বইগুলো একে অপরের থেকে কতটা কাছাকাছি। যদি দুইটি বই একই ধরনের বিষয়বস্তু সম্পর্কে হয়, তাহলে সেগুলো কাছাকাছি থাকবে।
সেমান্টিক সার্চের উদাহরণ
এখন কল্পনা করুন, আপনি লাইব্রেরিতে গিয়ে “সেরা মোবাইল ফোন ফটোগ্রাফির জন্য” খুঁজছেন। অ্যালেক্স এই প্রশ্নের পেছনে আপনার উদ্দেশ্য বুঝতে পারে—আপনি একটি ভালো ক্যামেরা সহ ফোন খুঁজছেন। সে তখন এমন বই বা ডেটা খুঁজে বের করবে, যা আপনার সার্চের সঙ্গে সম্পর্কিত, যদিও “সেরা মোবাইল ফোন ফটোগ্রাফির জন্য” এই শব্দগুলো সেখানে নেই।
অ্যালেক্স যখন আপনার সার্চ কোয়েরির জন্য ভেক্টর তৈরি করে, তখন সে এই ভেক্টরের মাধ্যমে সংরক্ষিত অন্যান্য ভেক্টরের সঙ্গে তুলনা করে এবং সেগুলো থেকে প্রাসঙ্গিক তথ্য রেজাল্ট হিসাবে বের করে নিয়ে আসে।
ভেক্টর ইনডেক্স এর প্রয়োগ:
সার্চ ইঞ্জিন: যেমন গুগল সেমান্টিক সার্চ ব্যবহার করে, ব্যবহারকারীর উদ্দেশ্য বুঝে সঠিক ফলাফল দেয়।
ই-কমার্স: যদি আপনি একটি টিভি খুঁজছেন, তবে সিস্টেমটি অন্যান্য গ্রাহকদের আচরণ অনুযায়ী প্রস্তাবিত পণ্য দেখাবে।
কাস্টমার সার্ভিস: ব্যবহারকারীর প্রশ্নের সঠিক উত্তর দিতে সেমান্টিক ইনডেক্স সাহায্য করে।
সংক্ষেপে
সেমান্টিক ইনডেক্স এবং ভেক্টর স্টোরেজ একটি নতুন দৃষ্টিকোণ থেকে তথ্যকে দেখতে সাহায্য করে। এটি শুধুমাত্র শব্দের উপর ভিত্তি করে নয়, বরং অর্থ ও সম্পর্কের মাধ্যমে তথ্য খুঁজে বের করে। ফলে, আপনি যখন তথ্য খোঁজেন, তখন আপনি আরো প্রাসঙ্গিক এবং কার্যকর ফলাফল পান, এবং এই পুরো প্রক্রিয়া একটি বড় ক্যানভাসে আঁকা ছবির মত—যেখানে প্রতিটি অংশ একে অপরের সঙ্গে যুক্ত।
সেমান্টিক ইনডেক্স বা ভেক্টর স্টোরেজ: এম্বেডিং কিভাবে কাজ করে:
======================
ধরুন, একটি ছোট শহরের একটি বইয়ের দোকান আছে, যেখানে বিভিন্ন ধরনের বই রয়েছে। এই বইগুলো শুধুমাত্র তাদের শিরোনামের জন্য নয়, বরং তাদের বিষয়বস্তু, অনুভূতি এবং তথ্যের জন্যও পরিচিত। কিন্তু বইগুলোকে সঠিকভাবে খুঁজে বের করতে হলে, কিছু বিশেষ পদ্ধতির প্রয়োজন।
এম্বেডিং: তথ্যকে ভেক্টরে রূপান্তর করা
একদিন, দোকানের মালিক মি. রাহুল বইগুলোকে আরও ভালোভাবে সংগঠিত করার সিদ্ধান্ত নিলেন। তিনি জানেন, প্রতিটি বইয়ের ভেতরে একটি “সত্তা” (essence) রয়েছে—একটি মূল ধারণা। তিনি একটি ম্যাজিক্যাল পদ্ধতির সাহায্যে বইগুলোকে সংখ্যা হিসেবে প্রকাশ করার সিদ্ধান্ত নিলেন। এই সংখ্যা গুলোকে ভেক্টর বলা যায়।
১. বইয়ের এম্বেডিং: একটি সংখ্যা তৈরি করা
মি. রাহুল প্রতিটি বইয়ের বিষয়বস্তু, চরিত্র, এবং গল্পের থিম বিশ্লেষণ করতে লাগলেন। ধরুন, একটি বইয়ের নাম “ভালোবাসার গল্প”। এই বইটির মূল ভাবনা এবং অনুভূতিগুলো বিশ্লেষণ করার পর তিনি এটি একটি ভেক্টরে রূপান্তর করলেন, যেমন (0.8, 0.1, 0.6)।
0.8: ভালোবাসা সম্পর্কিত বিষয়
0.1: দুঃখ
0.6: বন্ধুত্ব
এভাবে, প্রতিটি বইয়ের একটি ভেক্টর তৈরি হলো যা তার সত্তাকে উপস্থাপন করে।
২. ভেক্টর স্পেস:
মি. রাহুল এখন তার বইগুলোকে একটি বিশেষ জায়গায় সাজানোর সিদ্ধান্ত নিলেন, যেখানে প্রতিটি বইয়ের ভেক্টর একটি নির্দিষ্ট জায়গা দখল করবে। তিনি একটি 3D মডেল স্পেস তৈরি করলেন, যেখানে প্রতিটি বই ভিন্ন ভিন্ন স্থান দখল করে। এখানে, বইগুলো তাদের সম্পর্ক অনুযায়ী কাছাকাছি থাকবে।
ধরুন, “ভালোবাসার গল্প” বইয়ের পাশাপাশি “বন্ধুত্বের বন্ধন” বইয়ের ভেক্টর হবে (0.7, 0.2, 0.5)। এই দুটি বইয়ের ভেক্টরগুলো কাছাকাছি থাকবে কারণ তাদের মধ্যে সেমান্টিক সম্পর্ক আছে।
৩. সাদৃশ্য মাপা: তথ্য খুঁজে বের করা
এখন, যখন একজন গ্রাহক মি. রাহুলের দোকানে আসেন এবং বলেন, “আমি একটি ভালোবাসার বই খুঁজছি”, তখন মি. রাহুল তার প্রশ্নের ভেক্টর তৈরি করেন। ধরুন, তার প্রশ্নের ভেক্টর হবে (0.9, 0.1, 0.4)।
মি. রাহুল তখন বইয়ের ভেক্টরের মধ্যে সাদৃশ্য মাপেন। তিনি বইগুলোকে যাচাই করেন এবং দেখেন:
“ভালোবাসার গল্প” (0.8, 0.1, 0.6) → সাদৃশ্য: উচ্চ
“বন্ধুত্বের বন্ধন” (0.7, 0.2, 0.5) → সাদৃশ্য: মাঝারি
“দুঃখের গান” (0.1, 0.8, 0.1) → সাদৃশ্য: নিম্ন
এখন, মি. রাহুল “ভালোবাসার গল্প” বইটি গ্রাহককে দেখান, কারণ এটি তার অনুসন্ধানের জন্য সবচেয়ে উপযুক্ত।
ভেক্টর এমবেডিং এর প্রয়োগ:
.
সার্চ ইঞ্জিন: গুগল, যখন আপনি কিছু সার্চ করেন, তখন এম্বেডিংয়ের মাধ্যমে এটি আপনার প্রশ্নের ভিত্তিতে সম্পর্কিত তথ্য খুঁজে বের করে।
ই-কমার্স: বিভিন্ন পণ্য সাজাতে এবং তাদের মধ্যে সম্পর্ক বের করতে এম্বেডিং ব্যবহার করা হয়, যাতে ব্যবহারকারীরা তাদের প্রয়োজনীয় পণ্য সহজে খুঁজে পায়।
মেশিন লার্নিং: ডেটার মধ্যে সম্পর্ক খুঁজে বের করার জন্য এম্বেডিং ব্যবহার করা হয়, যা নতুন তথ্য বিশ্লেষণে সহায়ক।
সংক্ষেপে
মি. রাহুলের বইয়ের দোকানের গল্পটি আমাদের শেখায় যে কিভাবে এম্বেডিং বইগুলোর সত্তাকে ভেক্টরের মাধ্যমে প্রকাশ করে। এই ভেক্টরগুলো ভিন্ন ভিন্ন বইয়ের মধ্যে সেমান্টিক সম্পর্ক বুঝতে সাহায্য করে, এবং তথ্য খুঁজে বের করার প্রক্রিয়াটিকে সহজ করে। এম্বেডিং, তাই, তথ্য সংগঠন এবং অনুসন্ধানের একটি অত্যন্ত শক্তিশালী পদ্ধতি।
:::
3D স্পেসে ভেক্টর স্পেস বা একটা ডাটা পয়েন্ট থেকে অপর ডাটা পয়েন্ট এর দূরত্বের হিসাব কিভাবে হয়
===================
একটি ছোট্ট শহরের গল্প বলি, যেখানে একটি বিশেষ খেলার মাঠ ছিল। এই মাঠে তিনটি ভিন্ন রংয়ের লাইন ছিল: লাল, নীল, এবং সবুজ। এই লাইনগুলো শহরের ভিন্ন ভিন্ন দিক নির্দেশ করছিল। লাল লাইনটি পূর্ব-পশ্চিমের দিক, নীল লাইনটি উত্তর-দক্ষিণের দিক এবং সবুজ লাইনটি উপরের দিক। এই তিনটি লাইন মিলে একটি বিশেষ 3D স্পেস তৈরি করেছিল, যেখানে যেকোনো পয়েন্টকে সহজে চিহ্নিত করা যেত।
ভেক্টর স্পেসের মৌলিক উপাদান
১. ভেক্টর: পয়েন্টকে চিহ্নিত করা
একদিন, ছোট্ট এলিনা খেলার মাঠে এসে একটি নতুন খেলা শুরু করার সিদ্ধান্ত নিল। সে একটি পয়েন্ট চিহ্নিত করতে চাইল, যেটি মাঠের কেন্দ্র থেকে 3 ইউনিট পূর্ব, 2 ইউনিট উত্তর এবং 1 ইউনিট উপরে ছিল। এখানে এলিনা এই পয়েন্টটিকে ভেক্টর হিসেবে উল্লেখ করতে পারবে: (3, 2, 1)। এই ভেক্টরটি মাঠের মধ্যে সেই বিশেষ পয়েন্টকে চিহ্নিত করে।
২. ভেক্টর যোগ: নতুন পয়েন্ট তৈরি করা
এখন ধরুন, এলিনা তার বন্ধুদের সঙ্গে খেলতে চায়। যদি তার বন্ধু রাহুল 1 ইউনিট পূর্ব, 1 ইউনিট উত্তর এবং 2 ইউনিট উপরে থাকে, তাহলে রাহুলের ভেক্টর হবে (1, 1, 2)। এখন এলিনা ও রাহুল যদি একসঙ্গে খেলতে চায়, তাহলে তারা তাদের ভেক্টরগুলো যোগ করতে পারে।
ভেক্টর যোগ:
(3, 2, 1) + (1, 1, 2) = (3+1, 2+1, 1+2) = (4, 3, 3)
এখন তারা নতুন একটি পয়েন্টে পৌঁছেছে, যা (4, 3, 3)।
৩. ভেক্টরের দূরত্ব: বন্ধুত্বের পরিমাপ
এলিনা এবং রাহুল যখন মাঠে খেলছে, তখন তারা তাদের অবস্থান থেকে দূরত্ব মাপতে চাইল। ভেক্টরের মধ্যে দূরত্ব মাপা হয়। ধরুন, তারা তাদের পয়েন্টের মধ্যে দূরত্ব বের করতে চায়।
ভেক্টর স্পেস এর বাস্তব প্রয়োগ প্রয়োগ:
.
ফিজিক্সে: যেকোনো একটি পয়েন্টের উপর কাজের গতি নির্ধারণ করতে এই ভেক্টরগুলি কাজে লাগে।
কম্পিউটার গ্রাফিক্সে: 3D মডেল তৈরি করতে এবং তাদের মধ্যে পারস্পরিক সম্পর্ক বোঝাতে ব্যবহৃত হয়।
মেশিন লার্নিংয়ে: ডেটা পয়েন্টগুলোকে সঠিকভাবে চিহ্নিত করার জন্য ভেক্টর স্পেস ব্যবহার করা হয়।
সংক্ষেপে
এলিনা এবং তার বন্ধুদের খেলার মাঠের মাধ্যমে আমরা 3D স্পেসের ভেক্টর স্পেসের কাজ বুঝতে পারি। একটি ভেক্টর আমাদের একটি নির্দিষ্ট অবস্থান দেখায়, ভেক্টর যোগ আমাদের নতুন অবস্থানে নিয়ে আসে, এবং ভেক্টরের দূরত্ব আমাদের পারস্পরিক সম্পর্ক বুঝতে সাহায্য করে। এই গল্পটি আমাদের শেখায় যে ভেক্টর স্পেস কিভাবে একটি জগতের বিভিন্ন পয়েন্ট এবং তাদের মধ্যে সম্পর্ক নির্দেশ করে, ঠিক যেমন এলিনা এবং রাহুলের খেলায় ঘটে।
.
ভেক্টর স্টোরেজ ও রেজাল্ট র্যাংকিং:
=======================
.
তুমি যদি কুড়ি বছরের অভিজ্ঞ একজন শিক্ষক হও, এবং তোমার কাজ হলো জটিল বিষয়গুলোকে সহজভাবে ব্যাখ্যা করা, তাহলে ভাবো ভেক্টর স্টোরেজ এবং রেজাল্ট র্যাংকিং কীভাবে দৈনন্দিন জীবনের একটি সহজ উদাহরণ দিয়ে বোঝানো যায়।
.
ধরো, তুমি একটি বিশাল রেস্তোরাঁর মালিক, যেখানে হাজার হাজার ভিন্ন স্বাদের খাবার রয়েছে। এখন কেউ এসে তোমার কাছে একটি নির্দিষ্ট ধরনের খাবারের জন্য সুপারিশ চাইল। কিন্তু তারা সরাসরি কোনো খাবারের নাম বলেনি, শুধু বলেছে, “আমার এমন কিছু চাই যা মিষ্টি, হালকা, আর ঠান্ডা।” এখন, তোমার কাজ হলো এই রেস্তোরাঁর সমস্ত খাবারের মধ্যে থেকে সবচেয়ে উপযুক্ত খাবার খুঁজে বের করা।
এক্ষেত্রে, প্রতিটি খাবারকে তুমি একটি বিশেষ ভেক্টরের মাধ্যমে সংরক্ষণ করেছো। এই ভেক্টরগুলো প্রতিটি খাবারের বৈশিষ্ট্যকে প্রকাশ করে—মিষ্টতা, ঝাল, ঠান্ডা বা গরম, হালকা বা ভারি ইত্যাদি। যখন কেউ একটি নতুন রিকোয়েস্ট করে, তখন সেই রিকোয়েস্টের ভেক্টর তৈরি হয়, এবং তুমি এই ভেক্টরটি ব্যবহার করে সমস্ত খাবারের ভেক্টরের সাথে তুলনা করতে পারো। যেসব ভেক্টর বেশি মিলে যায়, সেই খাবারগুলোকে তুমি সাজিয়ে রাখতে পারো।
ভেক্টর স্টোরেজ কিভাবে কাজ করে:
======================
১. তথ্যকে ভেক্টরে রূপান্তর: প্রতিটি খাবারের জন্য ভেক্টর তৈরি করা হয়। যেমন, আইসক্রিমের ভেক্টর হতে পারে:
(মিষ্টতা = 0.9, ঠান্ডা = 1.0, হালকা = 0.8)।
২. ভেক্টর স্টোরেজে সংরক্ষণ: সমস্ত খাবারের ভেক্টর একটি বিশেষ স্টোরেজে রাখা থাকে, যা আমরা বলছি ভেক্টর স্টোরেজ। এখানে প্রত্যেকটি খাবার তার বৈশিষ্ট্য অনুসারে সংরক্ষিত।
৩. কাস্টমারের রিকোয়েস্ট ভেক্টর: যখন একজন কাস্টমার এসে বলে “মিষ্টি আর ঠান্ডা কিছু চাই,” তখন তার চাহিদাকে একটি ভেক্টরে রূপান্তর করা হয়:
(মিষ্টতা = 0.8, ঠান্ডা = 1.0, হালকা = 0.7)।
৪. সাদৃশ্য মাপা: এখন, এই রিকোয়েস্টের ভেক্টরের সাথে সমস্ত খাবারের ভেক্টর মেলানো শুরু হবে। মিলে গেলে তার মধ্যে যে ভেক্টরগুলো সবচেয়ে কাছাকাছি আসে, সেগুলোকে ধরা হয় সেমান্টিকভাবে বেশি সম্পর্কিত।
রেজাল্ট র্যাংকিং কিভাবে কাজ করে:
এখন, যখন সাদৃশ্য মেপে কিছু খাবার বের করা হলো, তখন তোমার কাজ হলো এই খাবারগুলোকে একটি বিশেষ ক্রমে সাজানো। যেমন, যেসব খাবারের ভেক্টর সবচেয়ে বেশি মিলেছে, তারা আগে আসবে। এই র্যাংকিং-এর ফলে কাস্টমার সবচেয়ে ভালো ফলাফল পাবে।
উদাহরণ:
ধরো, কাস্টমার মিষ্টি ও ঠান্ডা কিছু চেয়েছে, এবং ভেক্টর স্টোরেজে রাখা খাবারগুলো হলো:
আইসক্রিম:
(মিষ্টতা = 0.9, ঠান্ডা = 1.0, হালকা = 0.
ঠান্ডা লাচ্ছি:
(মিষ্টতা = 0.7, ঠান্ডা = 1.0, হালকা = 0.9)
কুলফি:
(মিষ্টতা = 0.8, ঠান্ডা = 0.9, হালকা = 0.7)
এখন, কাস্টমারের রিকোয়েস্টের ভেক্টরটি (মিষ্টতা = 0.8, ঠান্ডা = 1.0, হালকা = 0.7) এর সাথে এই তিনটি খাবারের ভেক্টরগুলোর সাদৃশ্য মাপা হবে, এবং যেটি সবচেয়ে কাছাকাছি আসে সেটি উপরে থাকবে।
আইসক্রিম:
0.9 এর কাছাকাছি, তাই এটি প্রথমে আসবে।
কুলফি:
এর সাথে 0.8 মিলে যায়, তাই এটি দ্বিতীয়।
ঠান্ডা লাচ্ছি:
এর সাথে 0.7 মিলে যায়, তাই এটি তৃতীয়।
এটাই হলো রেজাল্ট র্যাংকিং, যেখানে সবচেয়ে বেশি মিল থাকা আইটেম প্রথমে আসে।
ব্যবহারিক প্রয়োগ:
গুগল সার্চ: যখন তুমি কিছু খুঁজো, গুগল ঠিক একইভাবে তোমার রিকোয়েস্টের সাথে তার ভেক্টর স্টোরেজ থেকে তথ্য খুঁজে বের করে এবং র্যাংকিং করে দেয়।
ই-কমার্স সাইট: যেমন, অ্যামাজনে তুমি কোনো পণ্য খুঁজলে, পণ্যগুলোর বৈশিষ্ট্য অনুযায়ী তোমার রিকোয়েস্টের সাথে মেলানো হয় এবং র্যাংকিং করে সবচেয়ে ভালো মিলে যাওয়া পণ্যগুলো উপরে দেখানো হয়।
সংক্ষেপে:
ভেক্টর স্টোরেজ: এটি এমন একটি ডেটাবেস যেখানে প্রতিটি আইটেম বা তথ্য ভেক্টরের আকারে সংরক্ষণ করা হয়।
রেজাল্ট র্যাংকিং: মেলানো ভেক্টরের সাদৃশ্য অনুযায়ী আইটেমগুলো সাজানো হয়, ফলে সবচেয়ে প্রাসঙ্গিক ফলাফলগুলো আগে আসে।
* পরবর্তী পোস্ট পেতে কমেন্ট করুন next

