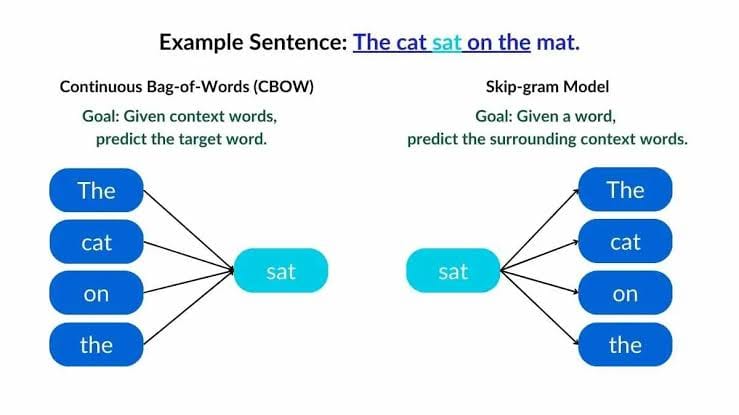
Continuous Bag of Words (CBOW) এর মানে কি
Continuous Bag of Words (CBOW) এর মানে কি
=====================
আচ্ছা, ধরো তুমি একটা ছোট গ্রামে থাকো। গ্রামে একটা বাজার আছে, যেখানে প্রতিদিন লোকজন বিভিন্ন জিনিস কিনতে আসে। তোমার কাজ হলো, বাজারে কে কী জিনিস কিনছে, সেটা খুব সহজে বুঝে ফেলা। ধরো, কেউ এসে যদি বলে “আমাকে বই দরকার,” তুমি বুঝে নেবে যে সে বই কিনতে চায়। কিন্তু কিছু মানুষ আছে, যারা আসলে পুরো বাক্যটা বলে না। যেমন, তারা শুধু “বই” শব্দটা বলে বা “দরকার” শব্দটা বলে। এখন তোমার কাজ হলো বাকিটা অনুমান করা।
এখন এই গল্পকে CBOW মডেলের সাথে মেলানো যাক। Continuous Bag of Words (CBOW) মডেলটা একধরনের ভাষাগত মডেল, যা কিছু নির্দিষ্ট শব্দের আশপাশের শব্দগুলো দেখে বুঝতে চায় কী আসতে পারে। যেমন, কেউ যদি বলে “আমি ___ খেতে চাই,” তুমি খুব সহজে অনুমান করতে পারো সেই ফাঁকা জায়গায় হয়তো “ভাত” বা “রুটি” আসতে পারে।
CBOW মডেলে, একটি বাক্যের মাঝে কিছু শব্দ বাদ দেয়া হয়, এবং সেই বাদ দেয়া শব্দ কী হতে পারে সেটা অনুমান করার চেষ্টা করা হয়। মডেলটি বাক্যের আশেপাশের (context) শব্দগুলো দেখে অনুমান করে। যেমন, বাক্যটি যদি হয় “বাচ্চারা মাঠে ___ খেলছে,” তুমি সহজেই অনুমান করতে পারো ফাঁকা জায়গায় হয়তো “ফুটবল” বা “ক্রিকেট” আসতে পারে, কারণ মাঠে এসবই খেলা হয়।
CBOW খুব সহজে কাজ করে: এটি প্রথমে চারপাশের শব্দগুলোর গড় (average) নিয়ে কাজ করে, তারপর সেই গড়ের ভিত্তিতে মধ্যবর্তী শব্দটা কী হতে পারে, সেটা অনুমান করে।
তুমি যেভাবে বাজারে মানুষের অসম্পূর্ণ কথা শুনে বাকিটা বুঝতে পারো, CBOW মডেলও ঠিক তেমনি অস্পষ্ট বাক্যগুলো থেকে প্রাসঙ্গিক শব্দ বুঝে নেয়।
এখন, ধরো এই মডেলটি ব্যবহার করে তুমি বাজারের সমস্ত মানুষের কথাবার্তার ভিত্তিতে তাদের ক্রয় করার অভ্যাস সম্পর্কে ধারণা পেতে পারো।
.
চারপাশে শব্দগুলোর গড় অথবা অ্যাভারেজ বের করে কি করে
—————————————-
আচ্ছা, ধরো, তুমি একটা ফুটবল দলের কোচ। তোমার দলে পাঁচজন খেলোয়াড় আছে। তাদের বয়সগুলো হচ্ছে ২০, ২২, ১৮, ২৪, আর ২৬ বছর। তুমি যদি জানতে চাও, এদের গড় বয়স কত, তাহলে কী করবে?
গড় বের করার জন্য তুমি প্রথমে সব বয়সগুলোকে যোগ করবে:
এবার মোট খেলোয়াড় সংখ্যা দিয়ে এই যোগফলকে ভাগ করবে:
তাহলে, গড় বয়স হলো ২২ বছর।
CBOW মডেলে ঠিক এভাবে কাজ হয়, শুধু এখানে বয়সের জায়গায় শব্দগুলোকে বিশেষ ধরনের সংখ্যায় (যাকে আমরা ভেক্টর বলি) রূপান্তর করা হয়। ধরো, “বই,” “খেলনা,” “পেন,” “ডেস্ক,” আর “কাগজ” — এদের প্রত্যেকটাকে সংখ্যায় রূপান্তর করা হয়েছে। যদি ধরো, “বই” = [1, 0, 0], “খেলনা” = [0, 1, 0], “পেন” = [0, 0, 1], তাহলে এই সংখ্যা (ভেক্টর) নিয়ে তাদের গড় বের করা হয়। এই গড়কে ব্যবহার করে মডেল অনুমান করে যে ফাঁকা জায়গায় কী শব্দ আসতে পারে।
এভাবে, চারপাশের শব্দগুলোকে সংখ্যায় (ভেক্টর) রূপান্তরিত করে, তারপর তাদের গড় বের করে মডেল ফাঁকা জায়গায় আসা সম্ভাব্য শব্দটা ঠিক করে।
================
শব্দগুলোকে ভেক্টরের রূপান্তরের প্রক্রিয়া সহজে ব্যাখ্যা কর
.
আচ্ছা, সহজভাবে ধরো, তুমি একজন দোকানি। প্রতিদিন তোমার দোকানে নানা ধরনের জিনিস বিক্রি হয়—যেমন, চকলেট, পেন, খাতা, আর খেলনা। এখন তুমি প্রত্যেকটা পণ্যকে একটা নম্বর দিতে চাও, যেন বুঝতে পারো কোন পণ্য কতবার বিক্রি হয়েছে। যেমন:
চকলেট: ১
পেন: ২
খাতা: ৩
খেলনা: ৪
এটা হলো পণ্যের একটা সাধারণ নম্বরিং সিস্টেম। এখন, শব্দগুলোকে ভেক্টরে রূপান্তর করার ধারণা অনেকটা এর মতো। ভেক্টরে, প্রতিটি শব্দকে অনেকগুলো সংখ্যা দিয়ে প্রকাশ করা হয়, যেমন একটা পণ্যকে একটা নম্বর দিয়ে। প্রতিটি শব্দের একটি ভিন্ন ভিন্ন বৈশিষ্ট্য থাকতে পারে, যেমন শব্দটি কতবার ব্যবহৃত হয়েছে, কতটা গুরুত্বপূর্ণ, ইত্যাদি।
ধরো, তিনটি শব্দ আছে: “বই,” “খাতা,” আর “পেন”। আমরা প্রতিটি শব্দকে তিন সংখ্যার ভেক্টর দিয়ে প্রকাশ করি, যেখানে প্রতিটি সংখ্যা বোঝায় শব্দটি বাক্যে কতটা প্রাসঙ্গিক। উদাহরণ হিসেবে:
“বই” = [1, 0, 0]
“খাতা” = [0, 1, 0]
“পেন” = [0, 0, 1]
এই ভেক্টরগুলো আসলে একেকটা বাক্যে একেকটা শব্দের অবস্থান বোঝায়। যেমন, যদি একটি বাক্যে “বই” থাকে, তাহলে “বই” এর ভেক্টরটি সক্রিয় হয়।
এখন ধরো বাক্যে “বই” এবং “খাতা” পাশাপাশি আছে, তাহলে এই দুই ভেক্টরের গড় বের করে দেখা যেতে পারে বাক্যে আর কী শব্দ থাকতে পারে।
এইভাবে প্রতিটি শব্দকে এক ধরনের সংখ্যায় রূপান্তর করে ভেক্টর বানানো হয়। মডেল এই ভেক্টরগুলোকে দেখে প্রতিটি শব্দের প্রাসঙ্গিকতা বুঝে।
=================
.
শব্দকে ভেক্টর বানানো হয় গণিতের কোন উপায়ে
.
শব্দগুলোকে ভেক্টরে রূপান্তর করার জন্য গণিতের কয়েকটি বিশেষ পদ্ধতি ব্যবহার করা হয়, যার মধ্যে সবচেয়ে জনপ্রিয় হলো One-Hot Encoding এবং Word Embedding (যেমন, Word2Vec বা GloVe)। আসো, আমরা সহজ করে এই পদ্ধতিগুলো দেখি।
১. One-Hot Encoding:
One-Hot Encoding পদ্ধতিতে প্রতিটি শব্দকে ০ এবং ১ দিয়ে প্রকাশ করা হয়। এটা অনেকটা ক্লাসরুমের ছাত্রদের উপস্থিতির মতো। যেমন, ধরো ক্লাসে পাঁচজন ছাত্র আছে—রবি, সোহেল, আনোয়ার, রাজিব, আর মেহেদী। তাদের নামগুলো যদি সংখ্যা দিয়ে প্রকাশ করা হয়, তাহলে দেখা যাবে যাকে উপস্থিত হিসেবে দেখানো হবে, শুধু তার নামের পাশে ১ থাকবে, আর বাকিদের পাশে থাকবে ০। উদাহরণস্বরূপ:
“রবি” = [1, 0, 0, 0, 0]
“সোহেল” = [0, 1, 0, 0, 0]
“আনোয়ার” = [0, 0, 1, 0, 0]
“রাজিব” = [0, 0, 0, 1, 0]
“মেহেদী” = [0, 0, 0, 0, 1]
এই পদ্ধতিতে প্রতিটি শব্দের জন্য শুধু ১টি অবস্থান সক্রিয় থাকে (১), আর বাকি সব জায়গায় ০ থাকে। এটা একটি সহজ পদ্ধতি, কিন্তু এর একটা সমস্যা হলো, এটি খুব বেশি জায়গা নেয় এবং শব্দের সম্পর্ক বোঝাতে পারে না।
২. Word Embedding (Word2Vec, GloVe):
Word Embedding একটি উন্নত পদ্ধতি, যেখানে শব্দগুলোকে অনেক ছোট এবং কার্যকর ভেক্টরে রূপান্তর করা হয়। এটি প্রতিটি শব্দকে একটি সংখ্যার তালিকা (ভেক্টর) হিসাবে প্রকাশ করে, যা শব্দগুলোর মধ্যে সম্পর্ক তৈরি করে।
Word2Vec:
Word2Vec হলো একটি মডেল, যা শব্দগুলোকে ভেক্টরে রূপান্তর করতে শব্দের কাছাকাছি সম্পর্ক বোঝায়। অর্থাৎ, একই ধরণের বা প্রাসঙ্গিক শব্দগুলো কাছাকাছি ভেক্টর হিসেবে থাকে। ধরো, “রাজা” এবং “রানী” শব্দ দুটি প্রায় কাছাকাছি অর্থ বহন করে, তাই তাদের ভেক্টরও কাছাকাছি হবে। আর “রাজা” ও “বই” দূরের সম্পর্কের, তাই তাদের ভেক্টরও দূরে থাকবে।
উদাহরণ:
ধরো, আমরা দুইটা ভেক্টর পেলাম:
“রাজা” = [0.4, 0.2, 0.8]
“রানী” = [0.3, 0.1, 0.9]
এই ভেক্টরগুলো দেখায় যে “রাজা” আর “রানী” প্রায় একই অর্থে ব্যবহৃত হতে পারে, তাই তাদের ভেক্টরের মান কাছাকাছি থাকে।
গণিতের ভিত্তি:
এই ভেক্টরগুলোকে গণিতের বিভিন্ন পদ্ধতি দিয়ে তৈরি করা হয়, যেমন:
Dot Product: শব্দগুলোর ভেক্টরের মধ্যে কতটুকু মিল আছে, তা বের করতে দুটি ভেক্টরের গুনফল নেওয়া হয়।
Cosine Similarity: এটি একটি পদ্ধতি, যা ভেক্টরের কোণ পরিমাপ করে বুঝতে চায় দুইটি ভেক্টরের মধ্যে সম্পর্ক কতটা ঘনিষ্ঠ।
সংক্ষেপে, Word Embedding পদ্ধতিতে গণিতের সাহায্যে শব্দগুলোর ভেক্টর তৈরি করা হয়, এবং এসব ভেক্টর শব্দগুলোর অর্থগত সম্পর্কগুলো বোঝায়।

All reactions:
You, Abdul Aouwal and 62 others