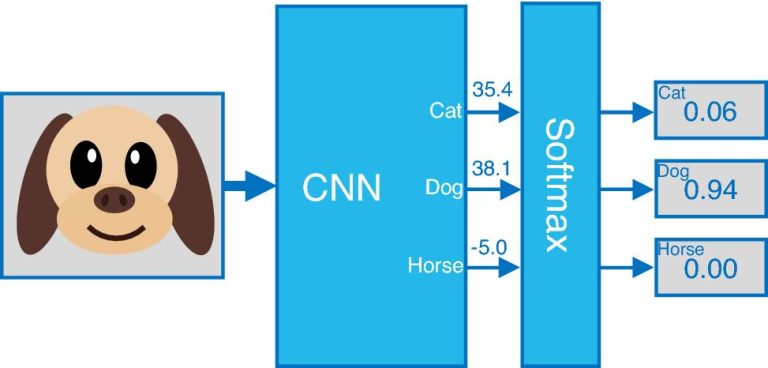
Reinforcement learning, Collective Intelligence, (Critical Thinking)
Collective Intelligence of human Species- মানব জাতির সমস্ত বুদ্ধিমত্তা একসাথে করলে যা হয় তা হল Collective Intelligence। এ আই এর উন্নতির কারনে এই বুদ্ধিমত্তা হুমকি/প্রশ্নের মুখোমুখি।
.
Reinforcement learning with human feedback
==============================
RLHF In machine learning, reinforcement learning from human feedback (RLHF) or reinforcement learning from human preferences is a technique that trains a “reward model” directly from human feedback and uses the model as a reward function to optimize an agent’s policy using reinforcement learning (RL) through an optimization.
.
ধরা যাক একটা নির্দিস্ট ডাটা/ স্কিলসেট দিয়ে একদল লোক কে ট্রেনিং দেয়া হল। ট্রেনিং এর পর তাদের দুই ভাগে ভাগ করে কাজে পাঠানো হল ইউজারদের সাথে কাজ করার জন্য। এক দল একটু ভাল করল, আরেক দল একটু খারাপ করল পারফরমেন্সে। যারা একটু খারাপ করল তারা বাদ পরে যাবে পরবর্তী টেনিং থেকে। কারণ এ খেলার সিস্টেম হল যে ভাল করবে শুধু সে টিকে থাকবে। এভাবে যারা ভাল করবে তারা ধারাবাহিকভাবে ট্রেনিং পেতে থাকবে এবং সুপার স্কিলড লেভেল এ পৌছে যাবে।
.
Base Model/ Base Capability: এ আই শুরুতে যা দিয়ে শুরু হয়েছিল তাই মূল মডেল বা বেজ মডেল। এই বেজ মডেল এর যে ক্ষমতা ছিল তা হল বেজ ক্যাপাবিলিটি। এরপর আসল বেজ মডেল কে ট্রেনিং দেয়ার পালা। ধরি ১ম মডেল কে পর্যাপ্ত ডাটা/টেক্সট/কোড খাবার হিসিবে দেয়া হল। এই খাবার খাওয়ার পর তার শারিরীক ক্ষমতা বাড়ল।
.
ধরি প্রথম জেনারেশনের জন্য-
১ম বেজ মডেল> ট্রেনিং ডাটা ফিড> রেজাল্ট ১ > আউটপুট ভাল
১ম বেজ মডেল> ট্রেনিং ডাটা ফিড> রেজাল্ট ২ > আউটপুট খারাপ
.
তাহলে এখানে উইনার কে?
উইনার হবে- ১ম বেজ মডেল> ট্রেনিং ডাটা ফিড> রেজাল্ট ১ > আউটপুট ভাল
.
দ্বিতীয় জেনারেশনের জন্য-
১ম জেনারেশন এর উইনার> ট্রেনিং ডাটা ফিড> রেজাল্ট ১ > আউটপুট খারাপ
১ম জেনারেশন এর উইনার>ট্রেনিং ডাটা ফিড> রেজাল্ট ২ > আউটপুট ভাল
সুতরাং
দ্বিতীয় জেনারেশনের জন্য- উইনার= রেজাল্ট ২> কারন এর আউটপুট ভাল
.
অতি সরলীকৃতভাবে এটাকে Reinforcement learning বলা যায়।
অরো অনেকগুলো থিওরিটিক্যাল বিষয় আছে এখানে। সহজভাবে বলার চেস্টা করব।
.
If you like the post, Comment- RLHF
ক্রিটিক্যাল থিংকিং (Critical Thinking) কী?
==========================
.
ক্রিটিক্যাল থিংকিং হল কোনও সমস্যা বা বিষয় পুরোপুরি বোঝার জন্য ঐ বিষয়ের বিভিন্ন তথ্য বিশ্লেষণের
মাধ্যমে একটা সিধ্বান্ত নেয়া। প্রথমে ধারণাটি পরিষ্কার হবে না। আস্তে আস্তে হবে। একটু সহজ করে বলা যায়-
.
-একটা সমস্যা থাকবে
– সমস্যাকে বোঝার চেস্টা/ উপায় থাকবে
– সাম্ভাব্য সমাধানের উপায় থাকবে
– পুরো বিষয়টিকে কি উপায়ে চিন্তা করা প্রয়োজন সেই চিন্তার পধ্বতি নিয়ে ধারাবাহিক ভাবনা থাকবে
– ভাবনাগুলো বাস্তবে কি ভাবে প্রয়োগ হবে তা থাকবে
– প্রয়োগ করতে যেয়ে কিছু সমস্যা হবে। সেই সমস্যাগুলো (Error) চিহ্নিত করতে হবে
– চিহ্নিত সমস্যাগুলো সমাধানের উপায় নির্ধারন করতে হবে (Error Fixation)
.
– এরপর কোন সমস্যা থাকলে তাকে প্রথম ধাপ থেকে পুনরায় শুরু করতে হবে। এই পর্যায় মূলত ফিডব্যাক বা এক ধরনের ফিডব্যাক লুপ (Feedback loop) । অর্থাৎ এই পর্যায় থেকে পুরো ব্যপারটি শুরু থেকে চক্রাকারে চলতে থাকবে। সমস্যাটি প্রথম ধাপ থেকে শেষ ধাপে যাবে এবং শেষ ধাপ পুনরায় প্রথম ধাপের সাথে যুক্ত হবে। প্রক্রিয়াটি কয়েকবার চললে ভুল (Error) এর পরিমান কমতে থাকবে এবং সমস্যাটি সমাধানের সাম্ভাব্য জায়গাতে পৌছানো যাবে।
.
পোস্ট ভাল লাগলে কমেন্ট করুন- think